Message queue is a well known architectural pattern that provide an asynchronous communication protocol. It means that sender and receiver of the message are completely detached, they do not need to interact with a queueing system at the same time.
It makes message queues (or message brokers) very useful for:
- decoupling of services
- painless scaling
- backpressure management
- operational visibility
All good, now comes interesting question.
How to choose a message broker?
There is no simple answer. Each system has it’s own set of requirements, development team, programming languages, etc. All these factors need to be considered.
In this post I want to focus on important factor which can be explained as nature of messages passed through the queueing system. Things like average message size and required throughput are very important but now the focus, more specifically, on the speed of message processing.
We’ll take two popular open source message brokers and see how they can be used for different types of messages. Message brokers:
- Kafka - high-throughput distributed messaging system
- RabbitMQ - reliable message broker (AMQP based)
Consumer speed is important
Message broker connects two types of processes: publishers and consumers. Consumer is the final destination point for any message, so the speed of message processing by the consumer determines overall throughput of the system.
Basically, to make things simple, we can classify consumers as “fast” and “slow”. This is very vague definition but good enough to understand basic concepts.
In order to help with defining our potential consumer as fast or slow, I suggest to look at the nature of messages passed though the system.
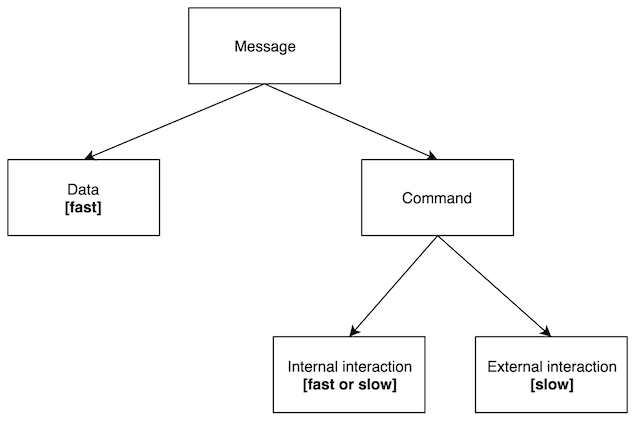
So, we can break down all messages into following large categories.
-
Data - message contains some piece of data, usually sufficient for consumer to perform the job. It means that consumer, usually, do not take additional input to process this message and can be classified as “fast”. Examples of data messages can be: log messages, metrics, web site activity events.
-
Command - message contains command to be executed by the consumer. It means that consumer need to perform some job which requires additional input or interaction with other components. The nature of this interactions can be different.
-
Internal interaction - consumer interacts with other components which can be called internal, they can be part of the same network, organization or system. This consumer can be “fast” or “slow” depending on how fast these internal components normally respond.
-
External interaction - consumer interacts with external components, they are outside of the system. Usually this type of consumer can be classified as “slow” because external interactions can introduce unexpected delays and sometimes failures.
-
Again, this is approximate classfication and every real system requires additional analysis.
Kafka or RabbitMQ
Good Kafka
First, Kafka has stellar performance. It outperforms RabbitMQ and all other message brokers. Tests show up to 100,000 msg/sec even on a single server, and it scales nicely as you add more hardware.
This is result of Kafka’s design:
- messages published to a topic are distributed into partitions
- messages in partition represented as a log stream
- consumer is responsible for moving through this stream
- messages from each partition are processed in-order only
In general Kafka is optimized for work with “fast” consumers. It can work with “slow” consumers pretty well, however partition-centric design has some consiquences that make dealing with some critical situations difficult.
The major limitation is that each partition can have only one logical consumer (in the consumer group). So it means that if we are working with “slow” messages single issue (slow processing) blocks all other messages submitted to this partition after that message. Different strategies can be used to resolve this issues, one of them is to run another consumer group and sychronize it with existing consumer somehow to avoid duplicated processing of messages.
Good RabbitMQ
RabbitMQ is mature product, easy to use, supports a huge number of developement platforms. It’s performance is not so impressive as Kafka’s, some tests show about 20,000 msg/sec on a single server. It also scales well when more servers added.
RabbitMQ is designed in a more classical way:
- messages published to queues (through exchange points)
- multiple consumers can connect to a queue
- message broker distribute messages across all available consumers
- message can be redelivered if consumer fails
- delivery order guaranteed for queues with single consumer (this is not possible when queue has multiple consumers)
So, we can say that this message broker can work well for “fast” consumers, if overall throughput is enough for your requirements.
And we have additional benefit in work with “slow” consumers. In the situation, when some consumer is stuck with some very slow processing, other messages will stuck in the queue as well unless we have other consumers connected. It means that by adding more consumers to the queue we are bypassing processing limitations. Usually this is a very simple operation, just run another process and RabbitMQ will take care about the rest.
Summary
Message queues is a broad and interesting topic, we just checked the tip of the iceberg here.
Conclusion is simple:
- Kafka is good for “fast” and reliable consumers
- RabbitMQ is good for “slow” and unreliable consumers
I recommend to use that for your analysis because real systems are more complex and above conclusion is not optimal for every situation.
Good luck!